@inproceedings{zhang2026orion,title={ORION: Option-Regularized Deep Reinforcement Learning for Cooperative Multi-Agent Online Navigation},author={Zhang, Shizhe and Liang, Jingsong and Zhou, Zhitao and Ye, Shuhan and Wang, Yizhuo and Tan, Derek and Chiun, Jimmy and Cao, Yuhong and Sartoretti, Guillaume},booktitle={In Submission},year={2026},}
GRATE: a Graph transformer-based deep Reinforcement learning Approach for Time-efficient autonomous robot Exploration
Haozhan Ni, Jingsong Liang, Chenyu He, and 2 more authors
IEEE International Conference on Robotics and Automation (ICRA), 2026
@inproceedings{ni2025grate,title={GRATE: a Graph transformer-based deep Reinforcement learning Approach for Time-efficient autonomous robot Exploration},author={Ni, Haozhan and Liang, Jingsong and He, Chenyu and Cao, Yuhong and Sartoretti, Guillaume},booktitle={IEEE International Conference on Robotics and Automation (ICRA)},year={2026},}
FARE: Fast-Slow Agentic Robotic Exploration
Shuhao Liao, Xuxin Lv, Jeric Lew, and 6 more authors
@inproceedings{liao2026fare,title={FARE: Fast-Slow Agentic Robotic Exploration},author={Liao, Shuhao and Lv, Xuxin and Lew, Jeric and Zhang, Shizhe and Liang, Jingsong and Li, Peizhuo and Cao, Yuhong and Wu, Wenjun and Sartoretti, Guillaume},booktitle={In Submission},year={2026},}
2025
HEADER: Hierarchical Robot Exploration via Attention-Based Deep Reinforcement Learning with Expert-Guided Reward
Yuhong Cao, Yizhuo Wang, Jingsong Liang, and 4 more authors
In Submission, 2025
Best Paper Award, Active Perception Workshop, IROS 2025
@inproceedings{header2025cao,title={HEADER: Hierarchical Robot Exploration via Attention-Based Deep Reinforcement Learning with Expert-Guided Reward},author={Cao, Yuhong and Wang, Yizhuo and Liang, Jingsong and Liao, Shuhao and Zhang, Yifeng and Li, Peizhuo and Sartoretti, Guillaume},booktitle={In Submission},year={2025},}
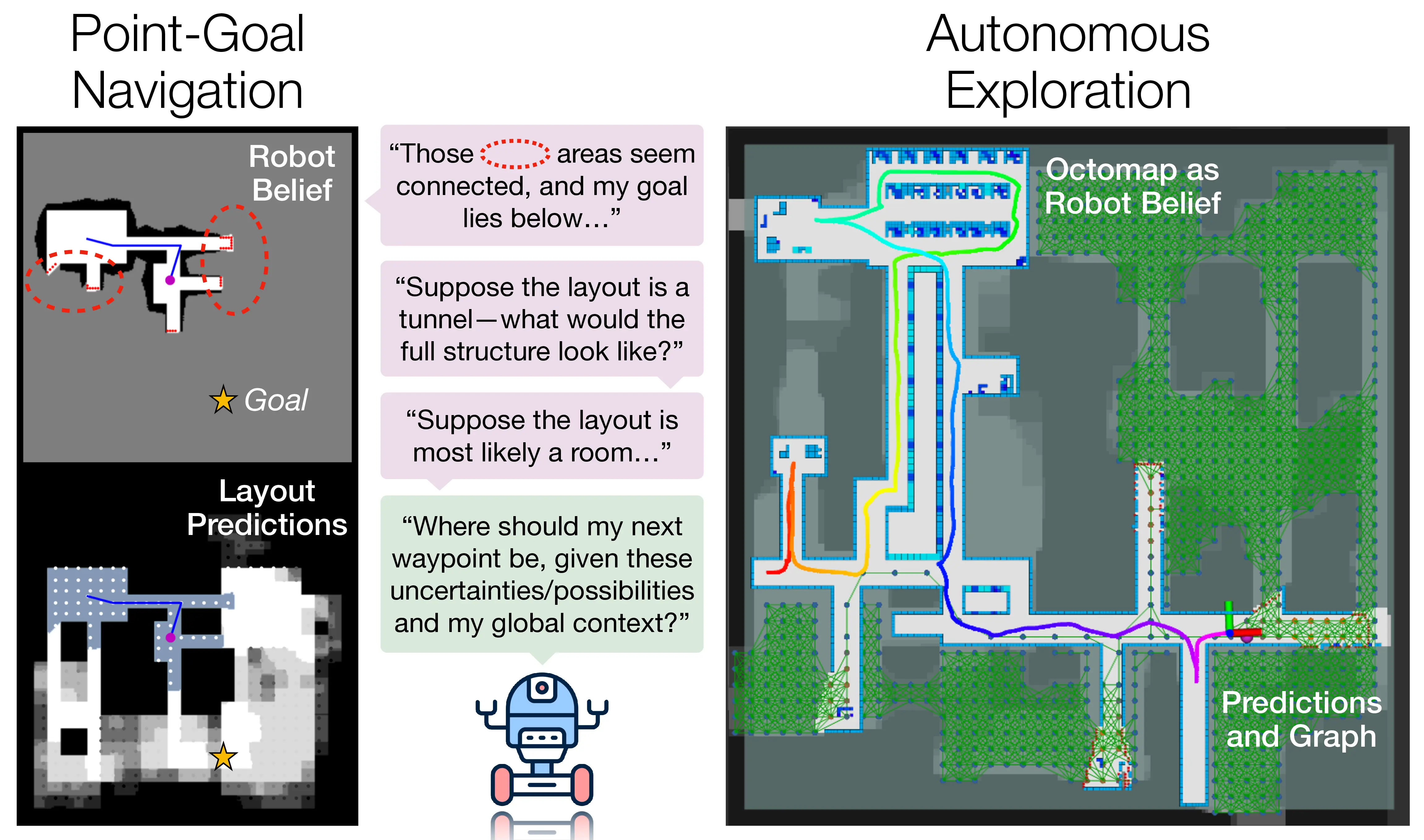
CogniPlan: Uncertainty-Guided Path Planning with Conditional Generative Layout Prediction
Yizhuo Wang, Haodong He, Jingsong Liang, and 3 more authors
@inproceedings{wang2025corl,title={CogniPlan: Uncertainty-Guided Path Planning with Conditional Generative Layout Prediction},author={Wang, Yizhuo and He, Haodong and Liang, Jingsong and Cao, Yuhong and Chakraborty, Ritabrata and Sartoretti, Guillaume},booktitle={Conference on Robot Learning (CoRL)},year={2025},}
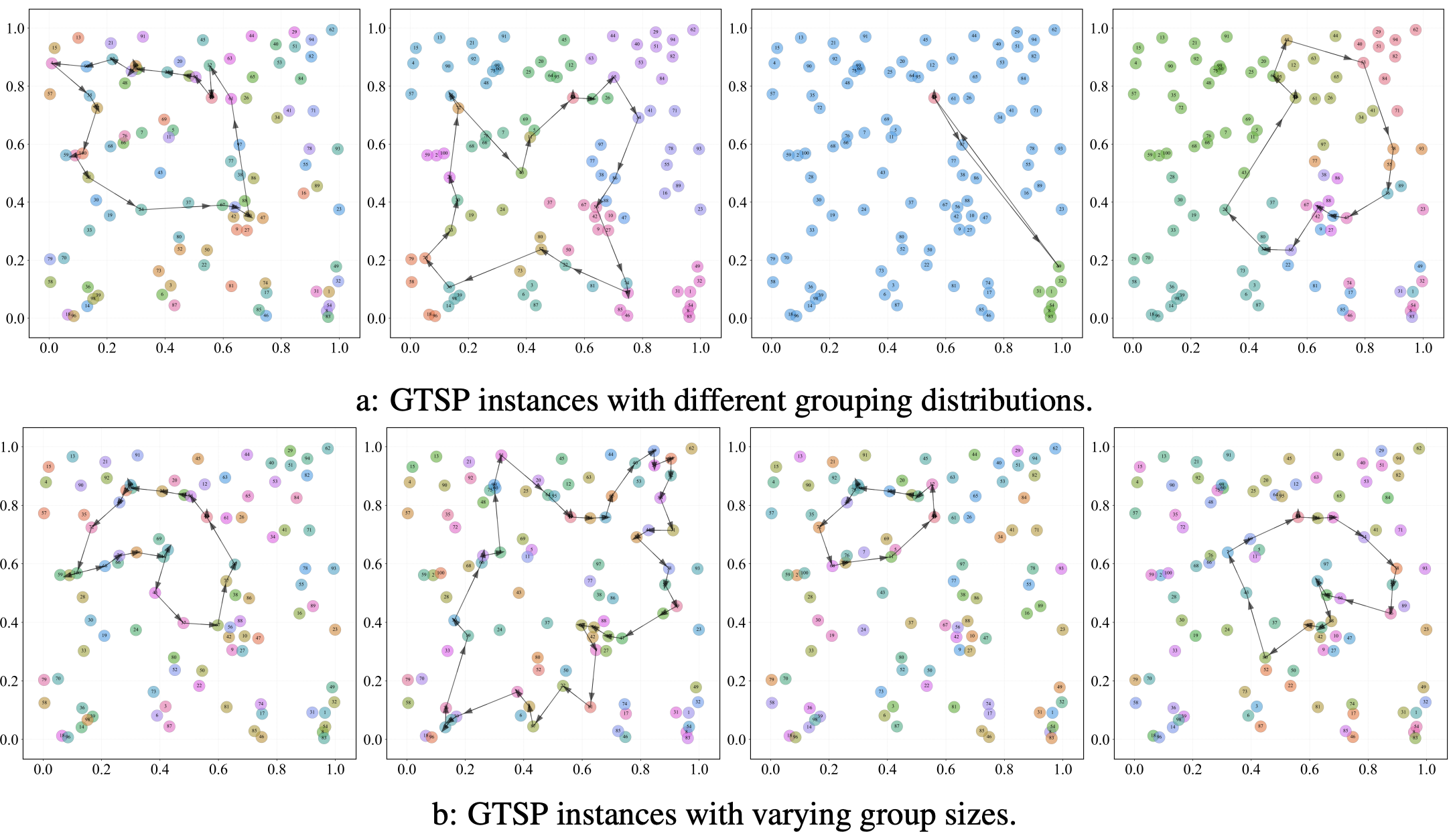
Multimodal Fused Learning for Solving the Generalized Traveling Salesman Problem in Robotic Task Planning
Jiaqi Cheng, Mingfeng Fan, Xuefeng Zhang, and 4 more authors
@inproceedings{cheng2025corl,title={Multimodal Fused Learning for Solving the Generalized Traveling Salesman Problem in Robotic Task Planning},author={Cheng, Jiaqi and Fan, Mingfeng and Zhang, Xuefeng and Liang, Jingsong and Cao, Yuhong and Wu, Guohua and Sartoretti, Guillaume},booktitle={Conference on Robot Learning (CoRL)},year={2025},}
DARE: Diffusion Policy for Autonomous Robot Exploration
Yuhong Cao, Jeric Lew, Jingsong Liang, and 2 more authors
IEEE International Conference on Robotics and Automation (ICRA), 2025
@inproceedings{cao2025dare,title={DARE: Diffusion Policy for Autonomous Robot Exploration},author={Cao, Yuhong and Lew, Jeric and Liang, Jingsong and Cheng, Jin and Sartoretti, Guillaume},booktitle={IEEE International Conference on Robotics and Automation (ICRA)},year={2025},}
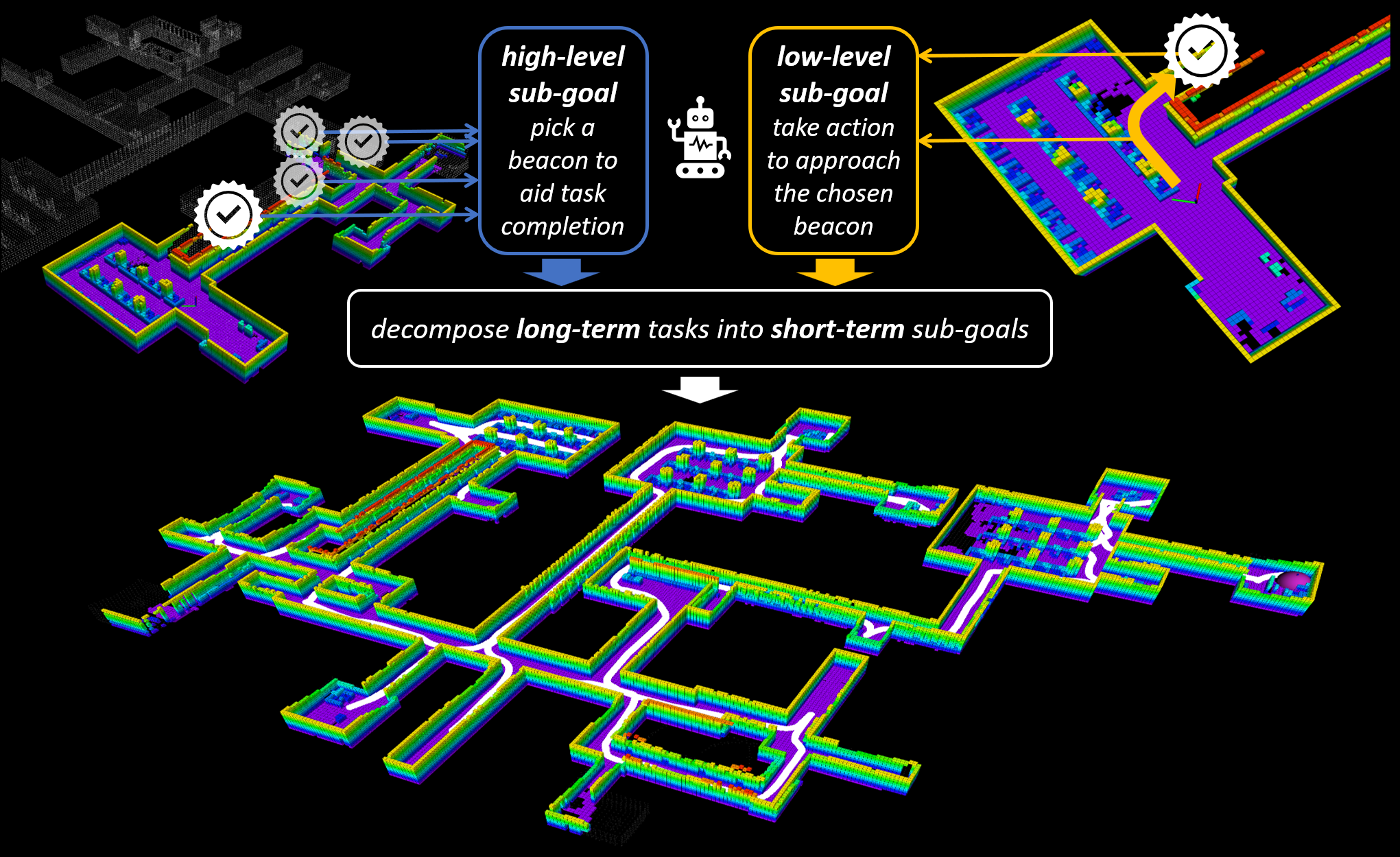
HDPlanner: Advancing Autonomous Deployments in Unknown Environments through Hierarchical Decision Networks
Jingsong Liang, Yuhong Cao, Yixiao Ma, and 2 more authors
@inproceedings{liang2024hd,title={HDPlanner: Advancing Autonomous Deployments in Unknown Environments through Hierarchical Decision Networks},author={Liang, Jingsong and Cao, Yuhong and Ma, Yixiao and Zhao, Hanqi and Sartoretti, Guillaume},booktitle={IEEE Robotics and Automation Letters (RA-L)},year={2025},}
2024
Privileged Reinforcement and Communication Learning for Distributed, Bandwidth-limited Multi-robot Exploration
Yixiao Ma, Jingsong Liang, Yuhong Cao, and 2 more authors
International Symposium on Distributed Autonomous Robotic Systems (DARS), 2024
@inproceedings{ma2024dars,title={Privileged Reinforcement and Communication Learning for Distributed, Bandwidth-limited Multi-robot Exploration},author={Ma, Yixiao and Liang, Jingsong and Cao, Yuhong and Tan, Derek and Sartoretti, Guillaume},booktitle={International Symposium on Distributed Autonomous Robotic Systems (DARS)},year={2024},}
IR2: Implicit Rendezvous for Robotic Exploration Teams under Sparse Intermittent Connectivity
Derek Tan, Yixiao Ma, Jingsong Liang, and 3 more authors
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
@inproceedings{derek2024ir2,title={IR2: Implicit Rendezvous for Robotic Exploration Teams under Sparse Intermittent Connectivity},author={Tan, Derek and Ma, Yixiao and Liang, Jingsong and Chng, YiCheng and Cao, Yuhong and Sartoretti, Guillaume},booktitle={IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},year={2024},}
2023
Context-Aware Deep Reinforcement Learning for Autonomous Robotic Navigation in Unknown Area
Jingsong Liang, Zhichen Wang, Yuhong Cao, and 3 more authors
@inproceedings{liang2023context,title={Context-Aware Deep Reinforcement Learning for Autonomous Robotic Navigation in Unknown Area},author={Liang, Jingsong and Wang, Zhichen and Cao, Yuhong and Chiun, Jimmy and Zhang, Mengqi and Sartoretti, Guillaume},booktitle={Conference on Robot Learning (CoRL)},year={2023},}